October 2, 2025
Cómo transformar los datos de transacciones financieras con machine learning

Si alguna vez has visto datos de pago sin procesar, sabrás que son un desastre. Un comercio puede aparecer de muchas formas distintas, repleto de prefijos de pago, registros de fecha y hora, términos legales y todo tipo de ruido adicional.
Este desorden dificulta que los bancos y las fintech ofrezcan a los clientes lo que esperan hoy en día: experiencias intuitivas y claras, información en tiempo real e implicación autentica basada en el comportamiento real.
Por eso es cada vez más importante un enfoque que combine datos de transacciones financieras y machine learning.
En Snowdrop, nuestro equipo ha estado trabajando para hacer frente a este reto, con una solución de Procesamiento del Lenguaje Natural (PLN ) específica del sector, diseñada específicamente para depurar secuencias de transacciones financieras y convertirlas en datos estructurados y procesables.
El reto de procesar los datos en bruto de las transacciones financieras
Veamos cómo son realmente los datos brutos de los comercios:
- FCB AG Ticketing, Muenchen, DE
- PULLBEAR 6505 CENTRUM.G, DRESDE, DE
- Gillet Tanken Waschen, Landau in der, DE
A los sistemas tradicionales les resulta difícil distinguir entre lo que es útil para el usuario final (la marca real) y lo que no es más que ruido (como “Ticketing”, “Centrum” o “AG”). Y olvídate de la
El procesamiento de lenguaje natural genérico no puede encargarse de esto. Y sin una comprensión sólida de la terminología específica del sector y del contexto regional, cualquier intento de enriquecimiento o contextualización fracasará.
En base a esto, ¿qué hemos desarrollado?
En lugar de intentar forzar modelos de Inteligencia Artificial de uso general en un contexto financiero, construimos algo desde cero: una herramienta ligera y de alta precisión, diseñada específicamente para datos financieros, que aprovecha el poder del aprendizaje automático.
Veamos cómo funciona:
- Token personalizado entrenado en millones de transacciones reales
- PMI (Información Mutua Puntual) para detectar términos multipalabra relevantes para la marca
- Inclusión de subpalabras de FastText para mejorar el reconocimiento de marcas poco comunes o mal escritas
- Diccionarios de dominios que clasifican los sufijos legales, los indicadores geográficos y los términos comerciales genéricos
Como resultado, nuestro sistema capta automáticamente lo datos importantes —la identidad de marca— y filtra todo lo demás.
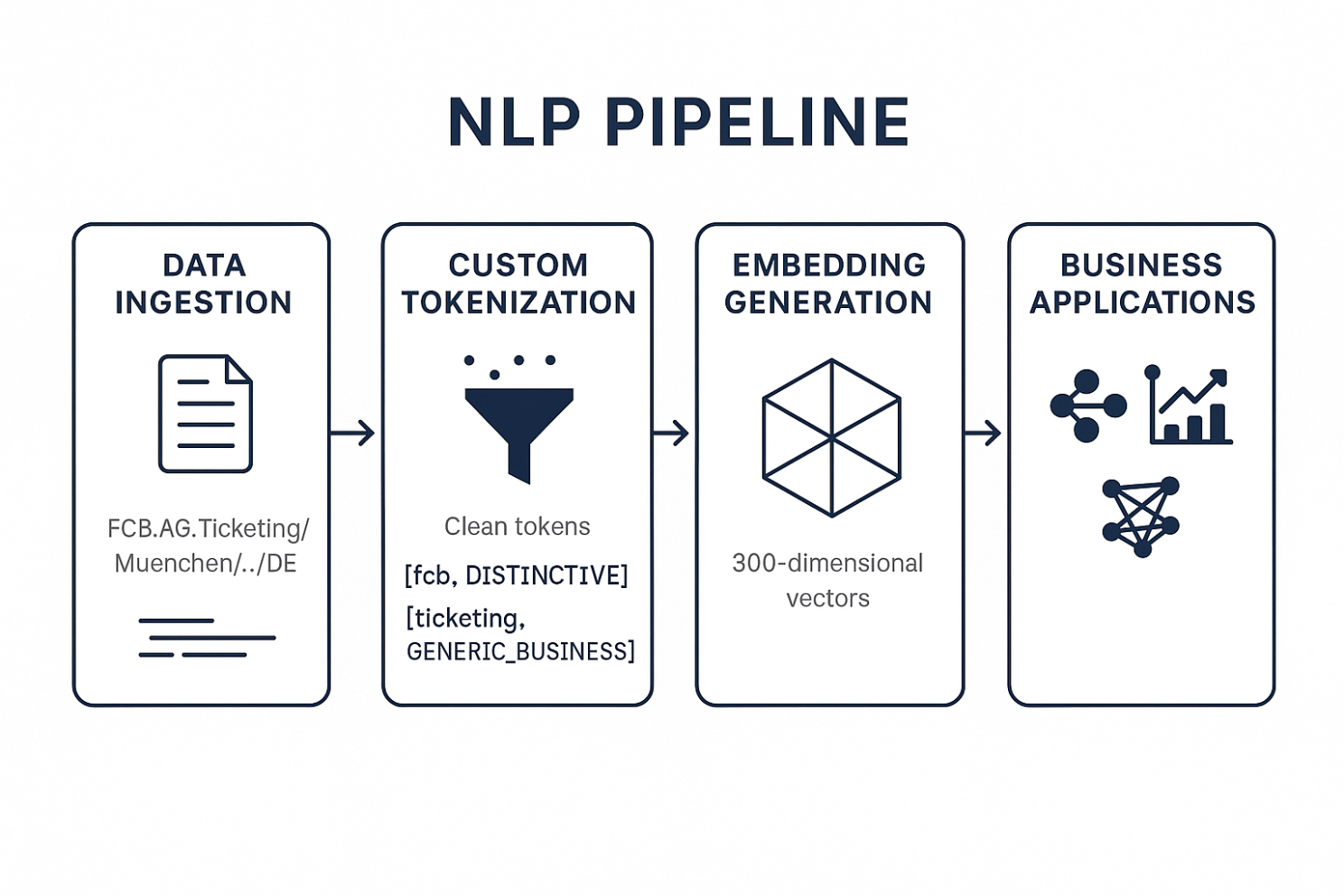
¿Qué hace esta solución inteligente? Machine learning en acción
Cada cadena de transacciones pasa por varias etapas:
- Limpieza y normalización
Elimina metadatos de pago como “KARTE 4012…”, registros de tiempo, puntuación aleatoria. - Detección de secuencias
Combina nombres de comerciantes de varias palabras en tokens limpios y unificados (por ejemplo, erlebnis_akademie). - Clasificación
Marca los tokens como distintivos o genéricos en función de lo raros o comunes que sean en nuestra base de datos. - Inclusión vectorial
Cada comercio enriquecido se convierte en un vector preciso de 300 dimensiones, perfecto para incorporarlo a modelos de aprendizaje automático, agrupación o cualquier tipo de análisis posterior.
En resumen, convertimos el desorden de una transacción en un perfil comercial estructurado, lo suficientemente limpio como para impulsar la personalización en tiempo real, la segmentación por comportamiento y la categorización automatizada a escala.
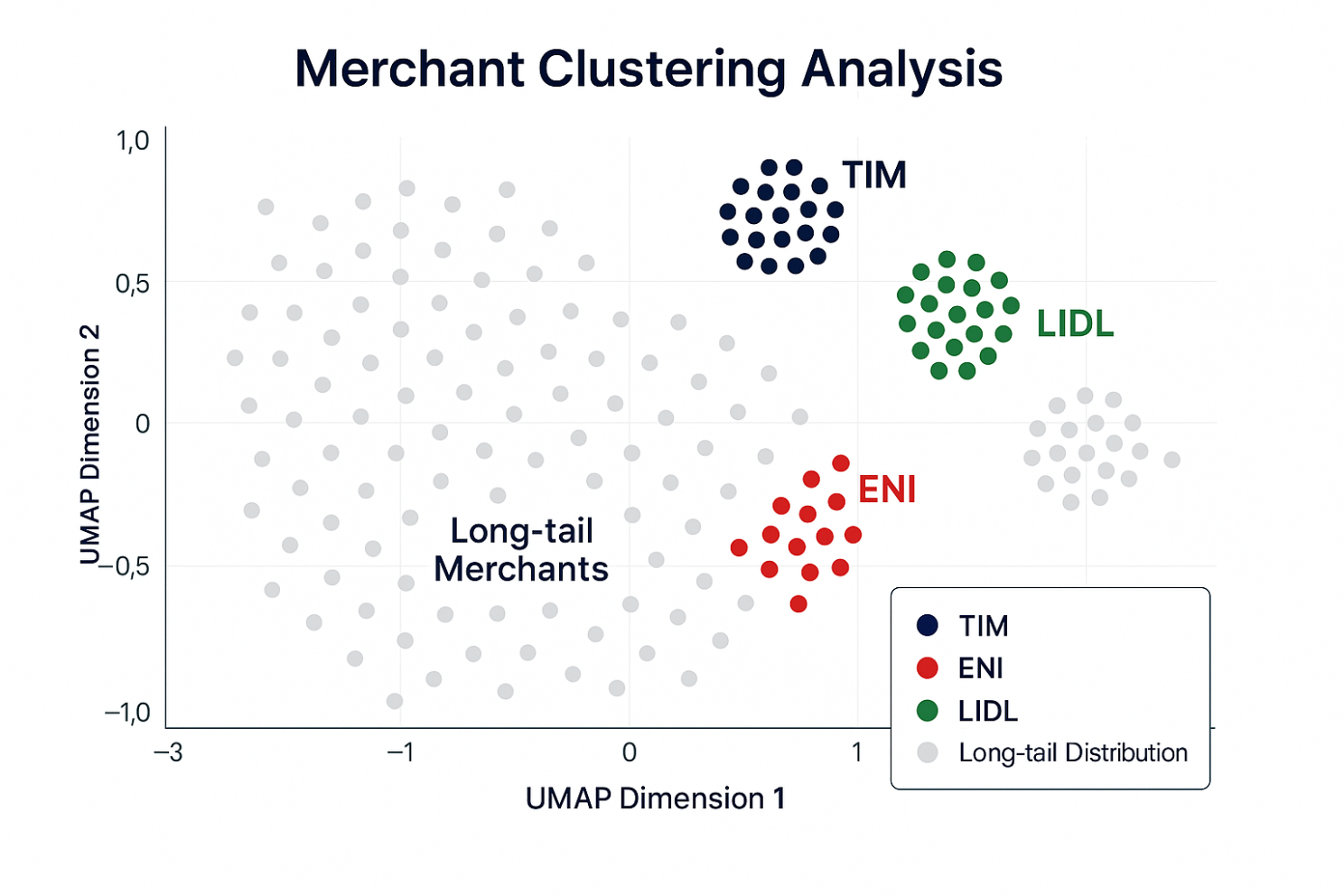
¿Cómo afecta a los bancos?
Tanto si tratas de reducir el tiempo de revisión manual como de poner en marcha la próxima experiencia de producto impulsada por la IA, disponer de datos de transacciones financieras limpios y enriquecidos marca una enorme diferencia.
Esto es lo que hemos conseguido:
➡️ incremento de +28% en las transacciones asignadas automáticamente a la marca correcta
➡️ Reducción significativa del trabajo manual: menos fricción, información más rápida
➡️ Identificación de comercios depurada que mejora la precisión de los análisis posteriores, los mecanismos de fidelización y las capas de personalización.
En otras palabras, hemos construido una plataforma que te ayuda a:
✅ Reconocer a los comercios con mayor precisión
✅ Categorizar el gasto automáticamente
✅ Segmentar a los usuarios en función de su comportamiento real
✅ Incorporar datos más precisos a tus herramientas impulsadas por la IA
Conclusión: La precisión es lo que cuenta
Los modelos genéricos de IA pueden ayudarte en parte, pero se pierden los matices. Nuestro enfoque es sencillo: empezar por la estructura de datos adecuada y, a continuación, incorporar la experiencia en el ámbito y el aprendizaje automático. Esto nos permite dar sentido a los datos de las transacciones financieras e impulsar un compromiso más inteligente y mejores resultados.
Creemos que el enriquecimiento de datos en tiempo real y específicos del dominio es la clave para desbloquear la próxima ola de innovación en banca, fintech y fidelización con el apoyo fundamental de machine learning.
Si estás interesado en desarrollar el futuro en las experiencias financieras, necesitas datos limpios, contextuales y procesables, desde el primer momento.

Chief Strategy Officer
Experienced CPO and CMO leader with drive, passion and a results-oriented approach to achieving the strategic vision. Extensive experience energising and motivating teams across all areas of product management, product marketing and corporate marketing.